
[Update (01-26-2023): The general thesis articulated in this examination has been invalidated by new discoveries which have come to light since the posting of this article.1 For the time being, I am leaving this piece up to serve as a witness to the progressive growth and evolution of my own understanding on this very important topic.]
Introduction
The orthographic diversity of the Masoretic text is perhaps one of the more agonizing thorns in the side of the Christian apologist seeking to defend the infallibility of Scripture. In this article I will demonstrate how ELS codes can be used to determine the objectively correct spelling of words which are spelled differently across manuscripts.
The Masoretic Text
All printed Hebrew Bibles and Old Testament translations today are based on what is known as the Masoretic text (MT). The Masoretic text is essentially the name of our “received text” of the Hebrew Old Testament. It is the direct descendant of an ancestor text-form which scholars often refer to as the proto-Masoretic text, which (thanks to the discovery of the Dead Sea Scrolls) we now know was one of a handful of consonantal textforms that were floating around Palestine during the late Second Temple period.
Sometime around the early second century, the proto-Masoretic text was chosen by the Jewish rabbinical establishment to become the official standard Hebrew textform of the Hebrew Scriptures. Shortly thereafter, the other consonantal textforms that had existed alongside the proto-Masoretic text ceased being re-copied and gradually fell out of circulation.2 The proto-Masoretic text was preserved and transmitted by the rabbinical establishment during the Talmudic period (ca. 100 – 500 CE), before it was finally taken up by the Masoretes (ca. 500 CE – 1000 CE) after whom it received its name. The most well known contribution of the Masoretes to this consonantal text was a system of vowel markers which they devised and added to the text. This was to ensure that the correct pronunciation of the Hebrew consonantal text would be preserved after Hebrew ceased to be a living spoken language.
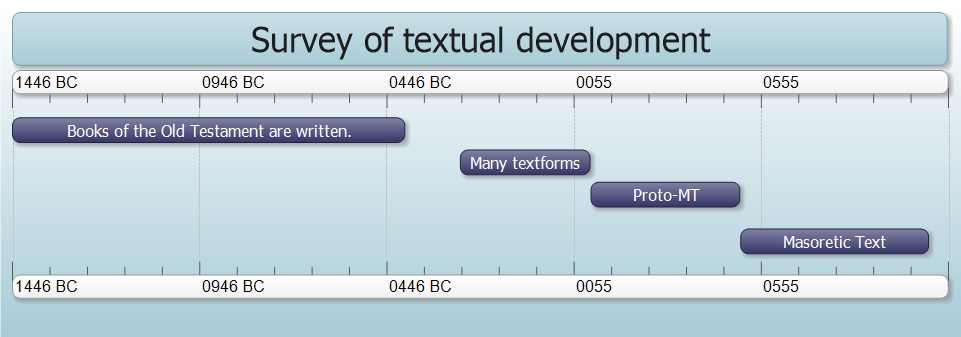
One text-form; many manuscripts
The fact that we refer to our received text by a single name can be misleading, as it tends to suggest one single textform that is based on a single hand-written manuscript. In truth, the MT is attested by numerous manuscripts–all of them dating to the Middle Ages. By far the most important of these are the Aleppo codex (ca. 930 CE), and the Leningrad codex (ca. 1004 CE), as these constitute the oldest complete (Leningrad) and nearly complete (Aleppo) manuscripts of the entire Hebrew Bible. Some other important manuscripts worth noting are: the British Museum 4445 (B), the Cairo Codex (C), Sassoon 507 (S), Sassoon 1053 (S1), and the Petersburg Codex (P).3
So far as the actual text is concerned, all of our extant manuscripts of the Masoretic text are in agreement. There is only one area in which they occasionally exhibit very minor disagreement, that being orthography. Specifically, the manuscripts occasionally disagree on how a particular word in a particular verse should be spelled, and we thus wind up with two different spellings of the word in different manuscripts. This is what I refer to as the problem of orthographic diversity.
Why the manuscripts occasionally exhibit minor orthographic disagreements
To understand why different Masoretic manuscripts might occasionally spell certain words slightly differently, one must have a basic understanding of Hebrew orthography. Unlike English and most other languages, the Hebrew alphabet is 100% consonantal, meaning that it does not contain any vowels. This of course does not mean that the Hebrew tongue doesn’t contain vowels (it would be impossible to speak a language without any vowels). Rather, Hebrew generally indicates vowel sounds using a system of vowel markers placed under, in, and above its consonantal letters. This is the system of vowel markers that was devised and added to the text by the Masoretes in the early Middle Ages.
While most vowels in Hebrew script are signified by a vowel marker, there are three particular vowels which are often (though not always) signified by a consonantal letter instead. These are the vowels corresponding to our English vowels of “i,” “o,” and “u.” Each of these constructions are noted in the table below (note that I used the silent letter Aleph in the vowel marker column):
| vowel sound | vowel marker | consonantal vowel |
| “ee” | אִ | אִי |
| “oh” | אֹ | אוֹ |
| ”oo” | אֻ | אוּ |
As indicated above, the “ee” vowel sound can either be presented by a dagesh in the middle of the letter,4 or by the consonant yod. Likewise the “oh” vowel sound can either be represented by a dagesh placed above the letter on the left side,5 or by the consonant vav with a dagesh above it. Finally, the “oo” vowel sound can be represented either by three dagesh placed below the letter in the diagonal orientation depicted in the table above,6 or by the consonant vav with a dagesh inside of it.
Because these particular vowels can be signified in writing two different ways, there are many words in Hebrew which can be spelled in two different ways—both of which are orthographically acceptable. The spelling which utilizes a traditional vowel marker to signify the vowel is known as the defective writing, while the one that utilizes the consonantal vowel is known as the full writing. So for example, the name David in Hebrew can be spelled two different ways. The defective writing for this name is דָּוִד, while the full writing is דּוִיד. Both spellings of this name are found in the Hebrew Old Testament, and both are orthographically correct.7
As previously stated, our concern is when one manuscript uses the defective writing of a particular Hebrew word in a given verse, while another uses the full writing of the same word in the same verse. Such instances reflect a lack of scribal consensus with regard to how a particular word in a particular verse should represent one of the three vowels which can be represented by either a traditional vowel marker or a consonant. Occasionally, the scribes who produced these surviving manuscripts disagreed, and the end result was that certain words wound up being spelled differently across manuscripts—usually by a single letter.8
Why Orthographic Diversity is a Problem
For verily I say unto you, Till heaven and earth pass, one jot or one tittle shall in no wise pass from the law, till all be fulfilled.
(KJV, Matthew 5:18)
The importance of Jesus’ words in the above verse cannot be overstated. It should be noted that the word “jot” here is the English rendering of the Greek word ιοτα (iota), which was the Greek letter equivalent of the Hebrew letter yod (י), which in the square Aramaic script adopted by the Jews about the time of Ezra—is the smallest letter in the Hebrew aleph-bet. Thus, the insinuation Jesus was making with this statement is that the Law (by which he means the Written Word in its entirety) is absolute, inviolable, and precise down to the tiniest letter. To word that slightly differently–there is not a single letter of Scripture which is not there by divine providence.
Jesus’ statement in Matthew 5:18 presents the Hebrew Scriptures as objective truth in the same rigid way that mathematics is objective truth, in that there is one objectively correct answer—and even the slightest deviation from that one right answer is wrong. So too, every word in the Bible has one objectively correct spelling; and even the slightest deviation from that one correct spelling is wrong.
If Jesus’ assertion about Scripture is literally true, then the orthographic diversity we find among the extant textual witnesses of our beloved Masoretic text obviously present us with a big problem. Although such minor orthographic differences do not alter either the pronunciation or meaning of any biblical passage, Jesus’ statement leaves no room for multiple correct spellings of any given word. For any given word where the spelling is disputed, only one spelling can be correct. This lack of orthographic uniformity forcibly confronts us with an obvious question, namely—which manuscript is the correct one, and how can we know?
How ELS codes can solve the problem of orthographic diversity
Whenever a word is spelled differently across manuscripts, the ELS codes which God has placed into the Old Testament enable us to determine which manuscript exhibits the correct spelling for the disputed word in question. The way that this works is simple–whenever a word in a given passage is spelled incorrectly, all authentic ELS codes in the passage which include the misspelled word in their letter count are inevitably destroyed. This means that all authentic ELS codes inevitably vanish from the manuscripts containing the misspelling, yet remain in the ones containing the correct spelling. Accordingly, by merely observing the effect that particular renderings of contested words have on authentic ELS codes, one can potentially identify and correct orthographic errors which have crept into the text over the course of transmission.
In order to better demonstrate how the process just described works in practice, let us consider some very basic examples.
Example 1
2 Chronicles 6:42 is one verse that contains a word that is spelled differently by a single letter in different manuscripts. This is the sixth word of the verse, which is spelled מְשִׁיחִךָ in the Aleppo codex (correct),9 and מְשִׁיחֶ֑יךָ in the Leningrad codex (incorrect). Charted below is a Type 1 ELS code I discovered several months ago which contains this word in its letter count:

Note that I have colored the word with the contested spelling in the above passage green to indicate that it is spelled correctly in this particular manuscript (the Aleppo codex). I am certain that it is spelled correctly because I am certain that the above ELS code is an authentic divinely planted ELS. This judgment rests on the fact that there is undeniable topical relation between the code and its containing passage. The fact that we have “the glory of the Lamb” encoded in four verses which speak of the glory of the LORD filling the Temple makes a strong case for the code’s authenticity by itself. Yet add to that the fact that this is only one of three passages in the entire Hebrew Bible where this 7 letter text-string is encoded at a standard ELS depth of 2 – 150 skips. Taken together, there is absolutely no realistic chance that this is a coincidental encryption.
Now notice what happens when we try to look for this same ELS code in the Leningrad codex:

As can be seen, the contested word in this particular manuscript includes 1 extra consonant. This has the effect of throwing the letter count off by 1, which inevitably destroys the ELS code. While in this particular case we still have a partial ELS code (“glory”)–this obviously falls far short of the glory of the complete intended encryption (pun intended) that we get when the word is spelled correctly.
Example 2
Another word with a contested spelling is found in 2 Chronicles 23:18. It is the third word of the verse, which is spelled פְּקֻדֹּת in the Leningrad codex (correct), and פְּקֻדּוֹת in the Aleppo codex (incorrect). The following Type 2 ELS code proves that the Leningrad contains the correct spelling in this particular instance:

Coincidence can be ruled out here for two reasons. First, the topical relation between the encoded text-string and its containing passage is obvious. The containing passage describes praise and worship occurring in the temple of God, and the central focus of the passage is about Jehoida the high priest turning the temple into (quite literally) a house of praise. The second reason that coincidence can be ruled out is that this is literally the only passage in the entire Hebrew Bible where this eight-letter text string is encrypted at a standard ELS depth of 2-150 skips. Taken together, we can be 100% certain that we are dealing with an authentic (divinely planted) ELS, and we can therefore be 100% certain that for this particular contested word–the Leningrad codex preserves the objectively correct spelling.
The figure below demonstrates how the incorrect spelling of the contested word in the Aleppo codex inevitably destroys the code:

Example 3
Hosea 2:17 is another verse in the Hebrew Bible which contains a word with a contested spelling.10 The contested word is the 16th word of the verse. The Aleppo codex spells this word עֲלוֹתָהּ (correct), while the Leningrad codex spells it עֲלֹתָהּ (incorrect). The Type 3 ELS code charted below proves that the Aleppo codex contains the correct spelling of this word.11

The topical relation between the encoded text-string and the containing passage should be obvious. This is a Type 3 ELS which echoes a key phrase, which in this case is “the beasts of the field.” The key phrase is encrypted letter-for-letter at an ELS of every 47 letters. Note also that this is the only passage in the entire Hebrew Bible where this particular 7-letter text string is encrypted at a standard ELS depth of 2-150 skips. In other words, coincidence in this case can be entirely ruled out. There is absolutely no question that this is an authentic biblical ELS, and this in turn tells us with 100% certainty that in this particular case–the Aleppo codex preserves the correct spelling of the contested word.
The figure below demonstrates how the incorrect spelling of the contested word in the Leningrad codex inevitably destroys the code:

A Word of Caution
When using ELS codes to identify orthographic errors in the Masoretic text, one must exercise extreme caution. It is absolutely imperative that you are 100% certain that the ELS codes you have identified are in fact authentic, by which I mean encrypted by God. If there is even a slight chance that the ELS in question could be a statistical coincidence–one cannot just assume that it is authentic and conclude that a word in the plain text is misspelled based on that mere assumption. Coincidences must be ruled out entirely.12
It should additionally be noted that the three examples I used to demonstrate how ELS codes can be used as spell-checkers all featured only a single encoded text-string. In practice, I do not conclude that a particular word in the Hebrew plain text of the containing passage is an orthographic error until I have positively identified a bare minimum of two or three authentic ELS codes in the passage. The reason for this is that when you have multiple ELS codes which include a particular word with a contested spelling in their letter count, all of those codes will be broken when the contested word is misspelled in a particular manuscript. This in turn means you have multiple cryptographic witnesses all telling you that the word with the contested spelling is misspelled. By the mouth of two or three witnesses let every word be established (Matt. 18:16; 2 Cor. 13:1).
None of our extant Hebrew manuscripts are orthographically perfect
When I first realized that ELS codes could be used to identify the correct spelling of words spelled differently across manuscripts, I was initially hopeful that I would be able to use the codes to determine which manuscript or edition of the Hebrew Scriptures was the “official” edition stamped with the Lamb’s own signet of divine authority. I reasoned that this edition would be the one that was completely free of orthographic blemishes. What I ended up finding instead was that there is no single orthographically perfect Hebrew textform currently in existence. Using ELS Bible codes, I have conclusively identified minor spelling errors in each and every medieval manuscript and every modern printed edition of the Masoretic text.13 Yet although no single earthly manuscript is orthographically perfect, God has gone out of his way to make sure that for every word with a contested spelling–the correct spelling is always attested by a minimum of two or three textual witnesses (Matt. 18:16; 2 Cor. 13:1; Deut. 19:15).
The Perfect Form of the Text
When Jesus indirectly stated in Matthew 5:18 that the Written Word is absolutely precise down to the tiniest letter, he was not referring to the original autographs which had long since perished. Rather, he was referring to the perfect form of the text that is forever settled in heaven (Ps. 119:89). Every earthly manuscript of the Masoretic text is an orthographically imperfect copy of this perfect form of the text which exists in heaven (Heb. 8:5; 9:24).
The text of both the Hebrew and Greek Scriptures have been in an ongoing process of textual purification throughout the entire process of their transmission. What this means is that the Scriptures as exemplified in our earthly hand-copied manuscripts have been moving along a progressive linear track from the time that they were penned by the biblical writers. This linear track begins with what we might call “the first drafts” (representing the original autographs of the biblical writers), all the way to what we might call “the final copies” (representing the perfect form of the text as it exists in heaven). Throughout this entire period of scribal transmission, the books of the Bible have been in an ongoing state of textual purification (Ps. 12:7), in which they are gradually becoming more and more like the perfect form of the text that exists in heaven as the sluggish process of their transmission marches forward. For thousands of years of transmission, the Lord has been slowly yet continually purging the text of its impurities by the hands of many anointed scribes, whose hands were unknowingly being moved by the Holy Spirit to make minor alterations (whether knowingly or unknowingly) to the text of the Hebrew and Greek Scriptures (Ps. 12:6).

In the same way that gold mined from the earth must first be purified and purged of its impurities in order to be made into something of value—so too the text of the biblical books had to be put through the purifying fires of textual sanctification in order to be purged of their orthographic impurities. In the same way that the body of Christ is continually being purified to become more and more like the perfect man who is seated on the throne in heaven, so too the body of Scripture is continually being purified to become more and more like the perfect form of the text that is forever settled in heaven (Ps. 119:89).14
Using ELS codes to amend the Masoretic Text
Given that none of our extant Hebrew manuscripts are orthographically perfect, the question naturally arises–can we use ELS codes to identify and correct all of the orthographic errors in the Masoretic Text, thereby allowing us to produce a perfected edition of the Hebrew Old Testament? Theoretically, it is possible–but it would be very difficult and would take a lot of unified brain power and many years of intensive research. The totality of my own personal research on ELS codes has gradually led me to the conclusion that any given Old Testament passage has a seemingly infinite number of authentic (divinely planted), contextually relevant, and prophetically meaningful ELS codes encrypted within its text at different letter skip intervals. It thus follows that if one could uncover enough undeniably authentic ELS codes to cover the text of the entire Old Testament, then one could theoretically correct all of the orthographic errors in the various manuscripts of the Masoretic text. One of the issues with that is that these codes can only be uncovered one at a time by running an ELS search for the exact encoded text-string (or at least a piece of it), and there really isn’t any way to choose which biblical passage you’re going to find them in. Thus, finding a sufficient number of ELS codes in all the right places to cover the entire text of the Old Testament is sure to take a very long time. Add to this the fact that each manuscript contains orthographic errors that will inevitably destroy authentic ELS codes that are supposed to be there, rendering the computer unable to find them. The only way around that is to not limit oneself to a single base text, and to manually search for each text-string in multiple textforms–making the entire process ever-the-more time consuming.
Despite the roadblocks just described, I remain convinced that ELS Bible codes are the divinely sent solution to the problem of orthographic diversity in the Masoretic text, and I am very passionate and excited about the possibility that they might some day be used to produce the first orthographically perfect edition of the Hebrew Old Testament.
 Copyright secured by Digiprove © 2021 Zerubbabel
Copyright secured by Digiprove © 2021 Zerubbabel
- Specifically, I am referring here to my assertions voiced in this article that the various manuscripts of the Masoretic text each contain orthographic errors, and that in any given instance Bible codes can be used to determine which manuscript contains the correct spelling of words spelled differently across manuscripts. These conclusions were based on the limited understanding I had on this subject at the time I penned this article. In hindsight I now know that this theory was incorrect, as the discovery of multiple long-distance Bible codes in two different manuscripts and one printed edition of the Hebrew Bible has forced me to conclude that no manuscript of the Masoretic text contains orthographic errors, because there is no exclusively “correct” spelling of words spelled differently across manuscripts. I now contend that each major manuscript and printed edition of the Hebrew Bible is uniquely divinely inspired–each being authenticated by its own unique set of divine watermarks of authenticity which are exclusive to the particular manuscript/edition of the Hebrew Bible in which they are found.
- Ellis R. Brotzman, in Old Testament Textuel Criticism: A Practical Introduction (Grand Rapids, MI: Baker Books, 1998), pp. 43-47.
- Brotzman, 56-58.
- The formal name for this vowel marker is Chiriq.
- The formal name for this vowel marker is Cholem
- The formal name for this vowel marker is Qibbuts,
- The name David is spelled defectively in the books of Samuel and the earlier prophetic books like Isaiah (Isa. 9:6) and Ezekiel (Ezek. 34:23), while the full spelling is used in the books of Chronicles and later prophetic books such as Zechariah.
- A consonantal vowel is a Hebrew letter which functions as a vowel. The letters yod and vav can be used to represent certain vowels.
- I am making an educated guess with regard to the vowel marker of the Chet here, as I do not have access to an edition of the Aleppo codex that includes the vowel markings.
- This verse is actually Hosea 2:15 in English Bibles
- Note that a search for this encoded text-string at a standard ELS depth of 2-150 letter skips yields only 1 positive search result–meaning that this is the only place in the entire Hebrew Old Testament where this complete text-string is encoded. This combined with the blatantly obvious topical relation between the encoded text-string and its containing passage proves without question that this is an authentic ELS code.
- I have a very strict set of criteria which I measure each and every code I find against to determine that they are authentic. If I have even a glimmer of doubt about the authenticity of a potential ELS code I have found, I do not record it. I will reveal the criteria I use to judge the authenticity of ELS codes in a future article.
- I must emphasize that these minor spelling errors only occur occasionally, and they do not in any way shape or form have any affect whatsoever on either the pronunciation or meaning of the text.
- One will note that this paradigm I have just articulated is radically different from the majority consensus view that most Christians inherit from the seminarians. This majority view (which I obviously do not agree with), says that only the original autographs of the biblical writers were wholly infallible. As such, any kind of error or blemish of any kind in our medieval Masoretic manuscripts—is attributed to the text being transmitted by imperfect human hands for so long. This belief is the doctrinal bedrock of biblical textual criticism, whose adherents seek in vain to reconstruct the text of the original autographs through an exhaustive comparative analysis of surviving manuscripts. Essentially, the key difference between the majority view and mine, is that the majority view sees the text as starting out perfect and gradually acquiring impurities (e.g. occasional spelling errors) over the lengthy course of transmission; while my view sees the text as starting out full of impurities and gradually being purged of them over the course of transmission. The reason I believe that my view is correct and the majority view is wrong, is because the number of divine watermarks in the original Hebrew and Greek manuscripts decreases the farther back one goes in the history of textual transmission. What this reveals is that such divine watermarks which attest to the Bible’s divine authenticity were being gradually being added to the Bible progressively over the course of transmission. This is evidence of divine inspiration occurring at the hands of the scribes and copyists who transmitted the Scriptures over the centuries, whose hands were unknowingly being guided by the Holy Spirit.